Continuous Migration
After having been involved in many migration projects over the last 10 years, I decided to publish the following White Paper in order to share my learnings.
The paper is titled Migrating to PostgreSQL, Tools and Methodology and details the Continuous Migration approach. It describes how to migrate from another relational database server technology to PostgreSQL. The reasons to do so are many, and first among them is often the licensing model.
From MySQL to PostgreSQL over the Week-End!
On February the 18th, 2015 I received a pretty interesting mention on Twitter:
Their story follows:
While this is awesome news for this particular project, it is still pretty rare that having to change your connection string is all you need to do to handle a migration!
If you’re less lucky than CommaFeed, you might want to prepare for a long running project and activate the necessary resources, both servers and people availability. Even if you’re using an ORM and never wrote a SQL query yourself, your application is still sending SQL queries to the database, and maybe not all of them can be written in a PostgreSQL compatible way.
Continuous Migration
Migrating to PostgreSQL is a project in its own right, and requires a good methodology in order to be successful. One important criteria for success is being able to deliver on time and on budget. This doesn’t mean that the first budget and timing estimates are going to be right — it means that the project is kept under control.
The best methodology to keep things under control is still a complex research area in our field of computer science, though some ideas seem to keep being considered as the basis for enabling such a goal: split projects in smaller chunks and allow incremental progress towards the final goal.
To make it possible to split a migration project into chunks and allow for incremental progress, we are going to implement continuous migration:
-
Continuous migration is comparable to continuous integration and continuous deployments, or CI/CD.
-
The main idea is to first setup a target PostgreSQL environment and then use it everyday as developers work on porting your software to this PostgreSQL platform.
-
As soon as a PostgreSQL environment exists, it’s possible to fork a CI/CD setup using the PostgreSQL branch of your code repository.
-
In parallel to porting the code to PostgreSQL, it’s then possible for the ops and DBA teams to make the PostgreSQL environment production ready by implementing backups, automated recovery, high availability, load balancing, and all the usual ops quality standards.
Setting up a continuous migration environment does more than allow for progress to happen in small chunks and in parallel with other work — it also means that your team members all have an opportunity to familiarize themselves with the new piece of technology that PostgreSQL might represent for them.
PostgreSQL Architecture
In order to be able to implement the Continuous Migration methodology, the first step involves setting up a PostgreSQL environment. A classic anti-pattern here is to simply host PostgreSQL on a virtual machine and just use that, putting off production-ready PostgreSQL architecture until later.
High Availability
A very classic PostgreSQL architecture to begin with involves WAL archiving and a standby server, and it looks like this:
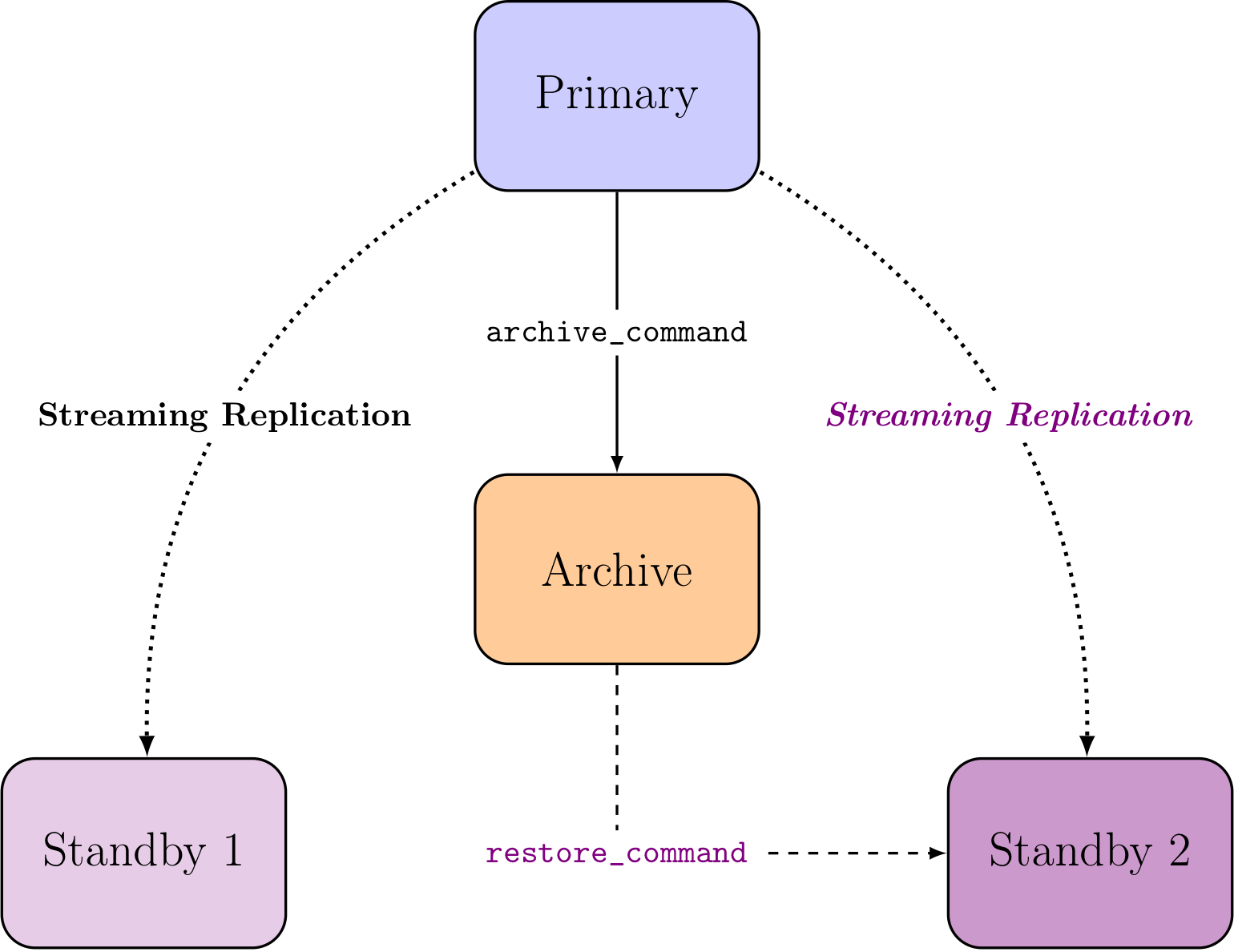
Automated Recovery
In the previous schema you can see the generic terms archive_command and
restore_command. Those PostgreSQL configuration hooks allow one to
implement WAL archiving and point in time recovery thanks to management of
an archive of the change log of your production database service.
Now, rather than implementing those crucial scripts on your own, you can use production ready WAL management applications such as pgbarman or pgbackrest. If you’re using cloud services, have a look at WAL-e if you want to use Amazon S3.
Don’t roll your own PITR script. It’s really easy to do it wrong, and what you want is an entirely automated recovery solution, where most projects would only implement the backup parts. A backup that you can’t restore is useless, so you need to implement a fully automated recovery solution. The projects listed above just do that.
PostgreSQL Standby Servers
Once you have an automated recovery solution in place, you might want to reduce the possible downtime by having a standby server ready to take over.
To understand all the details about the setup, read all of the PostgreSQL documentation about high availability, load balancing, and replication and then read about logical replication.
Note that the PostgreSQL documentation is best in class. Patches that add or modify PostgreSQL features are only accepted when they also update all the affected documentation. This means that the documentation is always up-to-date and reliable. So when using PostgreSQL, get used to reading the official documentation a lot.
If you’re not sure about what to do now, setup a PostgreSQL Hot Standby physical replica by following the steps under hot standby. It looks more complex than it is. All you need to do is the following:
- Check your
postgresql.confand allow for replication - Open replication privileges on the network in
pg_hba.conf - Use
pg_basebackupto have a remote copy of your primary data - Start your replica with a setup that connects to the primary
A PostgreSQL hot standby server replays its primary write ahead log, applying the same binary file level modifications as the primary itself, allowing the standby to be a streaming copy of the primary server. Also the PostgreSQL hot standby server is open for read-only SQL traffic.
It’s called a hot standby because not only is the server open for read-only SQL queries — this read-only traffic also doesn’t get interrupted in case of a standby promotion!
Load Balancing and Fancy Architectures
Of course it’s possible to setup more complex PostgreSQL Architectures. Starting with PostgreSQL 10 you can use Logical Replication. It’s easy to setup, as seen in the Logical Replication Quick Setup part of the PostgreSQL documentation.
Do you need such a setup to get started migrating your current application to PostgreSQL tho? Maybe not, your call.
Continuous Integration, Continuous Delivery
That’s how we do it now right? Your whole testing and delivery pipeline is automated using something like a Jenkins or a Travis setup, or something equivalent. Or even something better. Well then, do the same thing for your migration project.
So we now are going to setup Continuous Migration to back you up for the duration of the migration project.
Nightly Migration of the Production Data
Chances are that once your data migration script is tweaked for all the data you’ve gone through, some new data is going to show up in production that will defeat your script.
To avoid data related surprises on D-day, just run the whole data migration script from the production data every night, for the whole duration of the project. You will have such a good track record in terms of dealing with new data that you will fear no surprises. In a migration project, surprises are seldom good.
“If it wasn’t for bad luck, I wouldn’t have no luck at all.”
Albert King, Born Under a Bad Sign
We see how to implement this step in details in the Migrating to PostgreSQL, Tools and Methodology White Paper. Also, the About page of this website contains more detailed information about how pgloader implements fully automated database migrations, from MySQL, MS SQL or SQLite live connections.
Migrating Code and SQL Queries
Now that you have a fresh CI/CD environment with yesterday’s production data every morning, it’s time to rewrite those SQL queries for PostgreSQL. Depending on the RDBMS your are migrating from, the differences in the SQL engines are either going to be mainly syntactic sugar, or sometimes there will be completely missing features.
Take your time and try to understand how to do things in PostgreSQL if you want to migrate your application rather than just porting it, that is making it run the same feature set on top of PostgreSQL rather than your previous choice.
My book Mastering PostgreSQL in Application Development is a good companion when learning how to best use PostgreSQL and its advanced SQL feature set.
Continuous Migration
Migrating from one database technology to PostgreSQL requires solid project methodology. In this document we have shown a simple and effective database migration method, named Continuous Migration:
- Setup your target PostgreSQL architecture
- Fork a continuous integration environment that uses PostgreSQL
- Migrate the data over and over again every night, from your current production RDBMS
- As soon as the CI is all green using PostgreSQL, schedule the D-day
- Migrate without any unpleasant suprises… and enjoy!
This method makes it possible to break down a huge migration effort into smaller chunks, and also to pause and resume the project if need be. It also ensures that your migration process is well understood and handled by your team, drastically limiting the number of surprises you may otherwise encounter on migration D-day.
The third step isn’t always as easy to implement as it should be, and that’s why the pgloader open source project exists: it implements fully automated database migrations!






